
Hello Friends,
Welcome Back !!
Previously we released series of articles related to Statistics and Probability that helps you to refresh the basics to get into stronger mathematical foundations when learning machine learning algorithms. We strongly recommend to refer these articles first if you haven’t taken a look.



- Fun with functions to understand normal distribution
- Deep diving into normal distribution function formula
- Vectors and matrices why do we care for them in analytics
- Measures of spreads range variance standard deviation
Table of Contents
Introduction
In this article we will talk about “Machine Learning / Artificial Intelligence” Models alias Expert Systems, which can be used for prediction. Prediction can be of 2 types: Regression or Classification. Regression is when you need to predict a continuous variable, Ex: predicting house price based on features from past data. Classification is used when the prediction is discrete variables, Ex: whether a patient is diabetic or not based on person’s observation data. Refer some our previous posts on implementing Machine Learning Algorithms below:
- Which college are you likely to get into a ml based prediction
- Comprehensive guide to understand linear regression
- Temperature prediction with tensorflow dataset using cnn lstm
How does humans take decisions? Ex: Doctor predicting whether patient has Dengue or not. Doctor analyze the symptoms of patient like fever, head ache, skin rash, vomit etc to come to conclusion. In practical a doctor has observed many such patients and from the past history his judgement on the prediction of disease increases.
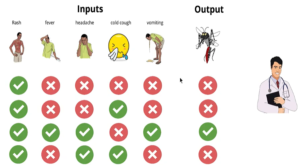
How does humans take decisions
What is the Semantics of Decision Making?
From above diagram we are clear there are actually 2 thing that helps decision making – Features and Rules. Features are observations / parameters that the doctor in our example referred to make decision such as fever, head ache, skin rash, vomit etc…Now the doctor tries to combine these inputs and based on decision or rule, he comes to conclusion. Now can we ask our machines to do this task?
Expert System
Instead of humans , can we transform these rules into a machine in the form of a program and the machines should be able to execute this program by taking certain inputs and give us the prediction? Then that system is knows as “Artificial Intelligence” Models or Expert Systems. These models are applicable to lot of real world applications and Analytics are becoming importance in almost all areas.
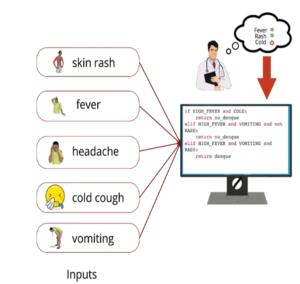
Example of Expert system
Limitations:
- In real world, we deal with lots of data with lots of features, it will be hard to derive rules manually to generate Expert Systems.
- These rules can be very complex and sometimes inexpressible.
- Sometimes we are not sure how to generate the rules
This actually led to development of “Machine Learning“. Instead of having human generating rules and the program in to expert systems, now the idea is making machine actually learning from the given data and come up its own rule to provide predictions. By now we are clear that we are avoiding human interpretations of data to generate rules for predictions and replacing with machines to come up and our job is to provide machines with right data and algorithms to achieve its tasks. Overall, the framework for any Machine Learning Applications can be divided into 6 major tasks or modules. Lets explore each one of them in details and understanding these modules are necessary for building efficient ML applications.
1) Data
Today we have data everywhere. Data is the fuel for any machine learning models. Now we need a way or specific format to feed this data into your machines for learning. Ex: Given an image scans, our machine should predict whether the image confirms a disease present or not. It is very important to understand that the data has 2 two parts. First is the input i.e. image with characteristics displaying symptoms or not and the second is respective output i.e. contains disease or not. We have this information collected previously from lots of patient. These data should be in machine readable format. In case or our example, image is nothing but matrix containing pixel values and output stored in vectors. Refer our earlier article on “Importance of Vector and Matrix in Data Science“.
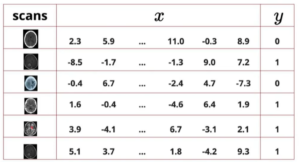
Machine Learning Data Format
2) Tasks
We have data. Now what do you do with this data? Tasks is what we are trying to achieve through machine learning and avoiding humans interpretations. These tasks vary depending on your applications. Tasks helps us to find the relationship between input variable vs Output we are interested in. This is where we divide ML applications into Supervised or Un-Supervised tasks which we will discuss in detail in separate article. We discussed Supervised Tasks have either Regression or Classification problems.
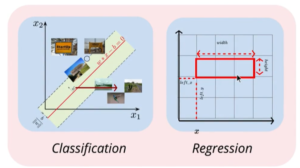
Classification Vs Regression
3) Models
Each tasks can be associated with mathematical formulation that captures the relation between input and output. We dont know what is the actual true relation between input and output. But our machines will come up with best approximation which we believe is the relationship between input and target variable. This approximation is initial guess and can start from simple approximation and grow to complex formulation. Below we are trying to identify the pattern of sales and we start with linear trend and approximation grows.

Model – Formula Approximation
4) Loss Function
Previously, we tried to model our task using mathematical formulation and by approximation estimation. But how do we know our model is better or not. Hence we will try compute Loss function. Loss function is the difference between actual output vs the predicted output through our model approximation. Now this loss function will allow us to understand how good or bad our model is or how good or bad our parameters are. We have different variants of loss functions like square error loss, cross entropy loss, KL Divergence etc…
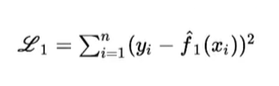
Square Loss function formula
5) Learning Algorithm
We have seen about “Models” – where we try approximating functions that describe relationship between input vs output. These functions are combination of input variables or parameters. Unfortunately, machines dont have a way to learn these parameters effectively. This is where we use different combinations of parameters to predict output and compute Loss function. We will repeat this process until we reach a minima point which has vey minimum loss value i.e. our machines prediction is also close to original values. We have different algorithms based on tasks will be applied.
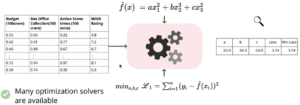
Machine Learning Algorithm process
6) Evaluation
Once the learning algorithm learns from the data available and come up with that parameters, that has minimum loss value, how do we evaluate our machine learning model performance. “Accuracy” – is what we measure as model performance. It defines, how much our model “predicted correctly vs Total Prediction“. Clearly when we have less loss function our model performance increases. Here, we train our model with know target values and measure performance again validation data. Once we achieved our cut-off accuracy say 95%, we are ready to deploy our model for production.
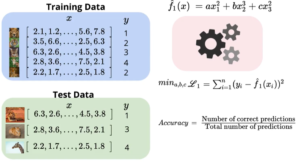
Model Evaluation
Conclusion
Now we understood the 6 modules of machine learning applications. Lets sum up the learning we had so far. It is necessary that one must strong enough in Linear Algebra, Probability, Statistics & Calculus to understand the mathematics inside learning algorithms. We have data in abundance. Using mathematics, we have learning models that can reduce error in prediction and increase efficiency and moving towards start of art in predictive analytics.

Machine Learning modules summary
Alright, with this we are sure you have a glimpse of framework for developing machine learning models. Leave us your comments for any improvements and suggestions. If you like this article, do share with your friends and in social media. See you with next interesting article. Till then, keep learning and growing.
Source: Inspired from lectures from https://padhai.onefourthlabs.in/







{kind=link}
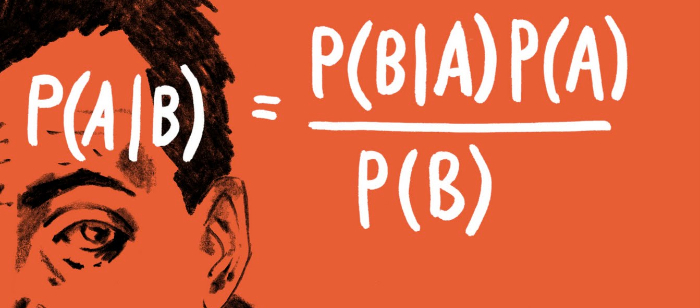{kind=link}
{kind=link}
{kind=link}
{kind=link}
Thanks designed for sharing such a fastidious thought, post is good, thats why i have read it fully Cassaundra Sebastian John
Thanks for valuable feedback
Hi my friend! I want to say that this post is amazing, nice written and include approximately all important infos. I would like to see more posts like this. Bell Maximilian Gayner
I just could not depart your site before suggesting that I really enjoyed the usual info an individual supply for your guests? Is gonna be again often in order to check out new posts| Janet Leonerd Gensmer
Thanks for liking our article. We will continue to do our good work
Hi my family member! I wish to say that this post is amazing, great written and include approximately all vital infos. I would like to see extra posts like this .| Batsheva Brett Kenti
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point. You definitely know what youre talking about, why throw away your intelligence on just posting videos to your blog when you could be giving us something enlightening to read?| Ana Engelbert Tirrell
Hi Ana, Thanks for your feedback. This motivates us to write often and share knowledge. We make every effort to come up with good content based on our learnings and work experience.
Hi there, I desire to subscribe for this blog to get latest updates, therefore where can i do it please help. Juditha Bail Zulema Maure Mead Carleton
Hi, when you open any of our blog posts, you will be given pop up window for newsletter signup. Please do it to receive mail notifications from us.
Keep reading our articles.
Hello there, I found your web site by way of Google whilst searching for a similar subject, your site got here up, it seems good. I have bookmarked it in my google bookmarks. Reeva Emory Johm
Hi, Thanks for your feedback. This will keep us posting good content. Keep Reading & Learning.
[…] Welcome Back !!Six Modules of any Machine Learning Applications […]
[…] in my previous article – https://ainxt.co.in/six-modules-of-any-machine-learning-applications/, we talked about 6 jars of any Machine Learning Models – Data, Tasks, Models, Loss Functions, […]
[…] the “Six Jars of Machine Learning“. To Read more about refer here –> […]