
Hello Friends,
Welcome Back !!
We all know “Interviewing” is important steps in candidate selection by any organization. It helps interviewer to evaluate candidate’s skills, experience and personality related to job requirements. Data Scientist’s are too no exception’s.
Generally there will be 2 or more technical discussion that assess candidate’s on on Python/R skills, SQL, Statistics, Machine Learning, Deep Learning, Projects worked & its outcome, etc…
These discussion vary based on organization, experience and job role you are applying for.
- https://ainxt.co.in/complete-guide-to-clustering-techniques/
- https://ainxt.co.in/which-college-are-you-likely-to-get-into-a-ml-based-prediction/
- https://ainxt.co.in/how-confident-are-you-with-confident-intervals/
- https://ainxt.co.in/measures-of-centrality-facts-and-insights/
Table of Contents
Introduction
There is variety of questions asked in data science interviews belonging to statistics, machine learning/deep learning algorithms, scenario-based questions, guestimates, etc.
Today, i taught of sharing some of my interview questions that faced during my selection process. These questions are something very fundamentals that we are unaware of its importance, yet we failed to notice!!
My intention is not to expose the questions, but “wanted to stress that, we as a data scientist often learn advanced analytics topics like NLP, Transformers, GAN’s, Ensembling, but forgetting the very basic fundamentals“.
Though we prepare and refresh our knowledge before appearing for the interview, some questions are very tricky and not able connect our intuitions to tackle it leading to rejection.
- https://ainxt.co.in/temperature-prediction-with-tensorflow-dataset-using-cnn-lstm/
- https://ainxt.co.in/understanding-feature-selection-for-model-accuracy-in-regression/
- https://ainxt.co.in/hands-on-exploratory-data-analysis-and-prediction/
Question – 1
Traditional Machine Learning involves Mathematical models used for Regression & Classification problems. Almost all Data scientist learn “Logistic Regression” algorithm used for Binary classification problem.
However, this particular question asked is something very fundamentals.
Question: “Explain why we need to Standardize Features before fitting Logistic Regression?”
I’m sure we all can explain what is Standardization. What is the difference between Standardization Vs Normalization.
We can also answer when standardization is used rather than Normalization.
But above question is deep diving in to logistic regression algorithm and make us to think what is the advantage of using standardization in features before fitting Logistic Regression Model.
It made me think a while and finally gave up after failing many attempts.
How do we approach this question ?
Intuition says, every Machine Learning algorithm is one or other way boils down to Optimization algorithm trying to reduce cost function. Whether this standardization helps in optimization ?
Optimization is Gradient Descent to find optimal values and converge to minima as possible.
Answer: “Feature values affect the step size of gradient descent. The difference in ranges of features will cause different step size for each feature. To ensure that the gradient descent moves smoothly towards the minima and that the steps for gradient descent are updated at the same rate of all the features, we scale the data before feeding it to model.”
Below links will give more idea on this question.
- https://builtin.com/data-science/when-and-why-standardize-your-data
- https://stats.stackexchange.com/questions/48360/is-standardization-needed-before-fitting-logistic-regression
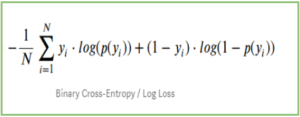
Question – 2
This Question i faced in interview is about Decision Tree Model.
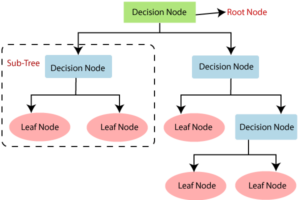
Decision Tree is a Supervised learning technique that can be used for both classification and Regression problems.
It is a tree-structured classifier, where internal nodes represent the features of a dataset, branches represent the decision rules and each leaf node represents the outcome.
In order to build a tree, we use the CART algorithm, which stands for Classification and Regression Tree algorithm.
We know the nodes are identified based on 2 functions. Either Entropy or Gini Index.
I have been asked below question,
Question: “In SciKit Learn Library by default GINI Index is used for splitting nodes, instead of Entropy. Why??”
Again, this question made me to think about my fundamentals on ML knowledge.
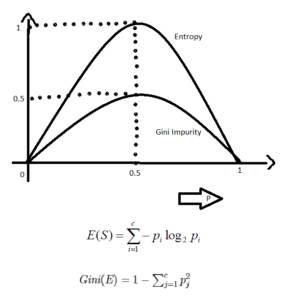
During interview, i recollected the formula for both Entropy & Gini Index, but not able to connect my intuition’s why GINI is preferred than Entropy by SciKit Learn Library and eventually give up.
Upon looking for answer, below article helped me to understand the difference.
Answer: “Computationally, entropy is more complex since it makes use of logarithms and consequently, the calculation of the Gini Index will be faster”
Obviously, programming is to achieve a task which is computationally cheap and faster. Hence in ML algorithms also default values are chosen such that optimally faster and cheaper.
Though this question is very simple and we learned Decision Tree algorithm, we miss to capture this minute details.
Question – 3
Python is mostly using in ML world and often interview’s test skill in python coding. We provide focus on learning data structures like Linked List, Trees, Graphs etc….
This question is again fundamentals, which focus on fundamental of Python.
Question – “Break the given sentence into words without using any functions”
Without doubt everyone recalls using Split Function provided by python or one can image using regular expressions to identify words, but these are built in functions.
This question again make us to go back to python fundamentals.
Answer:
Indexing is very important function in python. All we should do is identify the position of character to break and use indexing to extract and put in to a list using recursive function.
Though there are lot of ways, indexing turns out to be simple and effective.
Conclusion
Interview is tough for those who don’t prepare. Interview is tricky for those who prepare. Practice makes man perfect.
It is always advisable to revisit the fundamentals and stick the basic always. These questions which i faced in interview was sounding easy after referring the basics again.
so be always prepared.
We will continue to share our experience, till then KEEP LEARNING.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave A Comment