
Hello Friends,
Welcome back !!
In last couple of articles, we are getting deeper in “Deep Learning” concepts. Starting from Universal Approximation Theorem, How Gradient Descent Algorithm works & Use of Taylor Series, we discussed a lot.
Links for our previous articles to go through:
- https://ainxt.co.in/deep-learning-on-types-of-activation-functions/
- https://ainxt.co.in/importance-of-taylor-series-in-deep-learning-machine-learning-models/
- https://ainxt.co.in/learning-complex-functions-using-universal-approximate-theorem/
- https://ainxt.co.in/rethinking-probability-problem-using-natural-frequencies/
- https://ainxt.co.in/layman-understanding-of-gradient-descent-algorithm/
Today, wanted to discuss about making “Learning Algorithm Better” ??


Table of Contents
Introduction
Gradient Descent at the crux is to find & update new model weights such that error is reduced. Update rule as below.

New weights are obtained by subtracting new gradient descended weights multiplied with learning factor from old weights originally model used to learn.
Let us take a Error Surface plane with respect to Weight “W” & Bias “B”
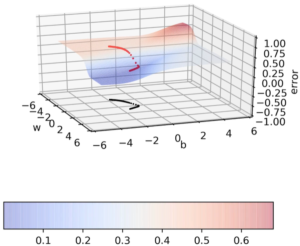 Notice how W, B values are varying for each epoch(No of passes of entire training dataset the machine learning algorithm has completed).
Notice how W, B values are varying for each epoch(No of passes of entire training dataset the machine learning algorithm has completed).
In Red region(Flat region), values of W & B are changing slightly. Likewise in Blue region(Slope), notice how W & B are changing rapidly.
Limitations of Gradient Descent
Why is this happening? Consider a slope function represented below.
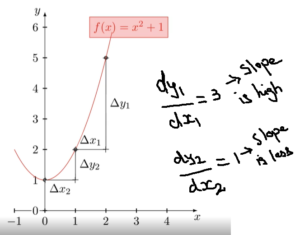
When slope is steep, derivative of Y with respect to X is higher value i.e. for value of 1 change in X resulting value of 3 change in Y.
However when Slope is flat, gradient is very less. This is what exactly happening in “Gradient Descent on the Loss function“.

“Since we initialize W & B randomly, we may end up in flat region”. If so, then we need more number of epoch’s to reach slope.
Therefore we need a better variant of Gradient Descent Algorithm.
Contour Maps
Contour Maps helps to visualize 2D error surface(front view). It represents Loss function θ in X axis & Error E in Y axis.
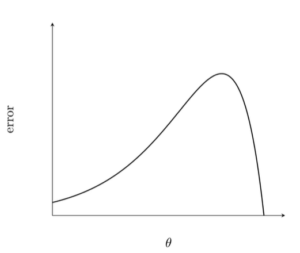
Lets make 2 horizontal slices in the plane and examine the region. If we look these horizontal slices from the top, it looks like elliptical circle.
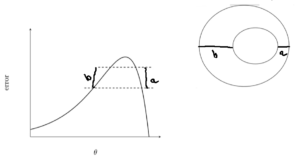
- A small distance between contours indicates a steep slope along that direction
- A large distance between contours indicates a gentle slope along that direction
With the help of Contour maps, we can visualize how the error surface is and how Gradient Descent Algorithm surfaces along the plane.
Momentum Based Gradient Descent
Intuition is if we go constantly in same direction then probably we gain some confidence to take bigger steps in that direction.
So, in “New Gradient Descent rule”, we introduce adding a History Component V(t).

V(t) is Gamma(Γ) times previous history. At every time step, instead of moving based on current gradient, we are also taking “exponentially decaying weighted sum of gradients“.
Is moving fast always good??
Nesterov Accelerated Gradient Descent
Because of momentum gained, GD oscillates in and out of the minima valley.
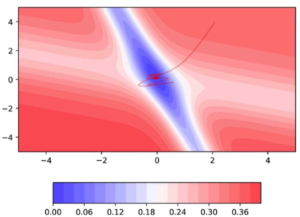
Can we reduced these oscillations ? Enter Nesterov Accelerated Gradient Descent.
Intuition is moving based on history component first and then compute derivative at that point

W(temp) is new location that moved based on momentum. Next we find the derivative at new location.
Looking ahead helps NAG in correcting its course quicker than momentum based gradient descent. Hence oscillations are smaller and chances of escaping the minima valley also smaller.
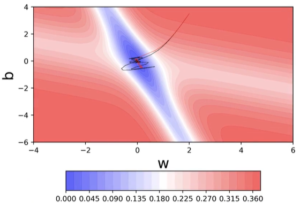
Conclusion
We learned plain vanilla gradient descent algorithm and how it works. Then, we saw the drawback of this algorithm and finding a way to make it better.
- Momentum Based Gradient Descent Algorithm
- Nesterov Accelerated Gradient Descent Algorithm
These algorithms basically uses history components and update weights resulting in Oscillations when reaching global minima.
In our next article we will look into other variants of Gradient Descent Algorithm.
Note: I have taken inspiration from IIT professor Mithesh Khapra’s original course on Deep Learning offered at https://padhai.onefourthlabs.in/ for this article.
https://amzn.to/3jpZIS4
https://amzn.to/3joxasi
To read more,
- https://ainxt.co.in/six-modules-of-any-machine-learning-applications/
- https://ainxt.co.in/measures-of-spreads-percentiles-facts-and-insights/
- https://ainxt.co.in/which-college-are-you-likely-to-get-into-a-ml-based-prediction/
- https://ainxt.co.in/complete-guide-to-clustering-techniques/






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave A Comment