
Hello Friends,
Welcome Back !! Our first post for the Year – 2022 :). After much thought, i decided to write about common interview question to “Explain about How Gradient Descent Algorithm Works ?”
I struggled a lot while answering this question as it always very hard to satisfy interviewer’s expectations. In this article, will walk through how Gradient Descent works.
We strongly recommend to read below of our articles, to get most out of this.
- Universal Approximation Theorem –> https://ainxt.co.in/learning-complex-functions-using-universal-approximate-theorem/
- Cross Entropy Loss Function –> https://ainxt.co.in/hidden-facts-of-cross-entropy-loss-in-machine-learning-world/
- Taylor Series for finding Gradient Descent –> https://ainxt.co.in/importance-of-taylor-series-in-deep-learning-machine-learning-models/
- Types of Activation Functions –> https://ainxt.co.in/deep-learning-on-types-of-activation-functions/
Table of Contents
Introduction
Remember the “Six Jars of Machine Learning“. To Read more about refer here –> https://ainxt.co.in/six-modules-of-any-machine-learning-applications/
- Data – Any information that is under our observation
- Task – Objective we are trying to achieve
- Models – Mathematical functions that captures relation between input vs output
- Loss Function – error between original value vs model predicted value
- Learning Algorithm – minimize loss function through weights & biases
- Evaluation – effectiveness of model
Loss Function L(θ)
Loss is the difference of ML model predicted value vs true value. Different loss functions are used for different types of machine learning problems aka models.
- Regression Models – RMSE (Root Mean Squared Error) Loss function is used
- Classification Models – CROSS ENTROPY loss function is used
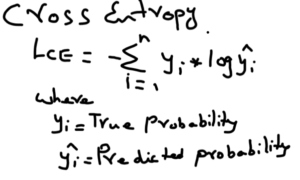
Gradient Descent
Gradient represents SLOPE of a curve at a given point in specified direction. In Deep Learning context, finding right values of weights (w, b) such that we reach global minima of loss value is known as “GRADIENT DESCENT“.
Once we have the loss function, we can find the derivative of Loss function with respect to w & b i.e. Δw =
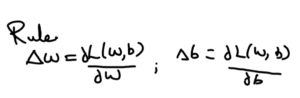
Chain Rule
Deep Learning is powered by mathematics and especially partial derivatives. We need to understand the chain rule, to understand the derivatives of loss function and backpropagate these loss.
With chain rule as shown below, we can break the equation and apply multiplication for each derivatives to get final output.
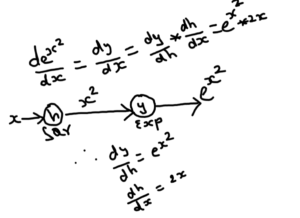
Chain Rule in Neural Network
Consider below neural network and we wanted to find derivative of loss function w.r.t weight at one of hidden network as highlighted. With the help of chain rule, we can breakdown the calculation as shown below.
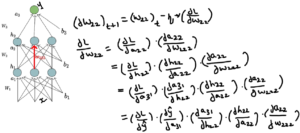
No matter how complicated the path of deep neural network is, with the help of chain rule we can calculate the partial derivative’s with respect the weights we are interested in. Once we find the derivatives, we can update our weights with the new value.
Similarly, we can reuse a lot of work by starting backwards and computing simpler elements in the chain.

Gradient Descent Learning Algorithm
Here are the steps of GD Learning Algorithm:
- Randomly initialize the Weights & Biases of Deep Neural Network that we have chosen for model training
- Based on the weights (w, b), model learns from input data and predicts output (ŷ)
- Compute the Loss Function L(θ) i.e. error value
- Next, compute the partial derivatives of loss function with respect to each of the weights in the neural network
- Multiply the output of partial derivatives with learning factor (η)
- Update the weights by subtract old weights with new partial derivative values
- Repeat from step 2 to step 6 again & again until we reach global minima of loss function i.e. no more reduction in loss value even if weights updated.

Efficient Gradient Descent Algorithm
Calculating derivatives of loss function with respect to each weights in neural network is bit tedious and we know that we can reuse previous layers derivatives. Hence in short we need to standardize the formula by finding
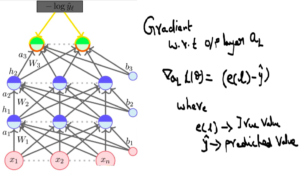
- Gradient with respect to output units
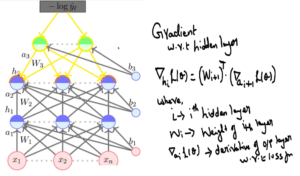
- Gradient with respect to hidden units
- Gradient with respect to weights and biases
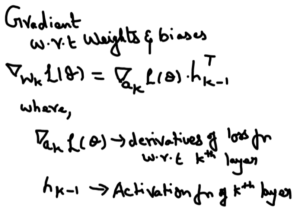
Recap
We have a generic neural network with “L” layers, “N” neuron for each hidden layers & “K” neuron at the output layer w.r.t to output classes. We use cross entropy function to compute loss & apply Gradient Descent algorithm for Back Propagation.
First we initialize Weights & Biases randomly and do forward propagation by using pre-activation(adding all weights & biases) & activation function(for non-linearity). At output layer, we apply “Softmax Function” for final prediction.
Next, we compute loss function using chosen loss function.
For Gradient Descent,
Calculate derivation of loss function with respect to output layer which is nothing but difference between true vs predicted output.
Now we will go all the way from last layer to first layer & finding partial derivatives w.r.t to each layer weights & biases & multiply with learning rate and subtract the derivatives from original weights.

Conclusion:
Almost every machine learning algorithm one or other way uses Gradient Descent Optimization to compute loss function such that our models performs better. I hope this article gives you a new source of information and do let us know your kind feedback to improvise further. I have taken inspiration from IIT professor Mithesh Khapra’s original course on Deep Learning offered at https://padhai.onefourthlabs.in/ for this article.
Do check his course for more information. We will back with next article, till then keep reading our other articles 🙂
- https://ainxt.co.in/deep-learning-on-types-of-activation-functions/
- https://ainxt.co.in/vectors-and-matrices-why-do-we-care-for-them-in-analytics/
- https://ainxt.co.in/understanding-feature-selection-for-model-accuracy-in-regression/
- https://ainxt.co.in/complete-guide-to-clustering-techniques/






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
[…] Layman Understanding of Gradient Descent Algorithm!! […]